嵌入式AI开发与部署
近年来,随着计算机AI软件技术的突破以及嵌入式硬件性能的提升,通过边缘计算设备部署小规模AI模型以更好解决工业界实际问题的思路,得到了越来越多的关注。
常见应用场景包括:门禁机的人员识别, 停车场的车牌识别,录音设备中语音转文字等。
本文将简要介绍在嵌入式(边缘计算)设备中常规算法开发方案与模型部署流程,共分为两部分:算法模型的获取与模型的落地部署。
算法模型
此部分内容简述,不再详细展开
主要为 需求分析→数据采集与处理→模型获取。
需求分析
将业务所需功能划分或拆解为对应类别的算法模型,复杂需求往往需要多个算法模型有序执行才能达成目标。
明确具体需求并设定具体的期望效果,是解决问题的第一步,也是最关键的一步。
计算机视觉领域常见问题模型分类:
1、图片识别(Image Classification)
2、目标检测(Object Detection)
3、语义分割(Semantic Segmentation)
4、视频理解(Video Understanding)
5、图片生成(Image Generation)
常见需求分解:
- 人员跟踪 = 人员检测模型(如YOLO)+ 物体跟踪模型(MOT)
- 人脸识别 = 人脸区域检测模型(如RetinaFace) + 矫正人脸姿态模型(关键点定位模型)+ 人脸比对模型(相似度比对模型)
部分场景下,为保障精度及稳定性,往往需要通过多种不同的检测方式获取结果,并对比较差验证与校准:驾驶员行为检测算法 = 人脸识别算法 + 抽烟玩手机等危险动作识别 + 面部疲劳驾驶检测 + 车道线偏移检测(用以进一步校准);
人员存在检测=基于图像的人员存在检测+基于毫米波雷达的硬件检测。
随着需求复杂度的增加,实现难度也会递增。例如相对于人脸识别相较于人员检测更为复杂。
因此明确需求和目标效果至关重要,也是解决问题的第一步。
数据采集与处理
根据需求和目标,确定需要采集的数据类型和特征,确保数据多样性以提高算法的泛化能力。
数据集不必在一开始就准备完全,可以在模型训练过程中根据实际效果优化和添加样本数据。
最后仍需要对数据进行清洗和标注,保证数据的质量,以便模型训练与处理。
模型获取
目前,大多数问题都有对应的底层模型,选取适当的底层模型可以加速问题的解决。在采集到数据后,还通过进一步微调模型结构,利用自定义数据集提升模型在特定场景下的准确性。
对于同一问题,基本上业界已存在大量的解决方案,它们在精度,速度,落地可行性等方面各有优劣,研发人员应关注领域进展,积累经验,并根据模型的分析与部署不断优化。
值得注意的是,并非所有问题均需要通过复杂的深度学习模型来解决,在部分场景下,传统的图像处理方案往往能达到更好的效果。
模型落地与部署
模型的转换、量化与性能评估、前处理与后处理、算法模块封装、模型部署与优化,以及业务逻辑开发构成了完整的部署流程。
以下重点介绍转换、量化与性能评估环节。以瑞芯微芯片为例,详细讲解模型部署的步骤。
模型转换
瑞芯微提供的RKNN-Toolkit2工具支持将多种框架(如Caffe、TensorFlow、ONNX等)训练的模型转换为RKNN格式,以充分利用NPU加速推理。
量化
量化概念
将浮点模型量化为定点模型
不同精度模型
低精度模型表示模型权重数值格式为FP16(半精度浮点)或者INT8(8位的定点整数),但目前低精度往往就指代INT8。
常规精度模型则一般表示模型权重数值格式为FP32(32 位浮点,单精度)。
混合精度(Mixed precision)则在模型中同时使用FP32和FP16的权重数值格式。FP16减少了一半的内存大小,但有些参数或操作符必须采用FP32格式才能保持准确度。
量化优点
模型量化主要意义就是加快模型端侧的推理速度,并降低设备功耗和减少存储空间。
- 减小模型大小
如int8量化可减少 75% 的模型大小,int8量化模型大小一般为 32 位浮点模型大小的 1/4: - 减少存储空间:在端侧存储空间较小时更具备意义;
- 减少内存占用:更小的模型当然就意味着不需要更多的内存加载模型空间;
- 减少设备功耗:内存耗用少,推理速度自然会更快,也就减少了设备功耗;
- 加快推理速度
访问一次32位浮点型可以访问四次int8整型,整型运算比浮点型运算更快; - 特殊的,某些硬件加速器如 DSP/NPU 只支持 int8
比如有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化。
模型评估与优化
模型推理
在设备上进行推理并获取推理结果,瑞芯微官方提供了 Python 和 C 语言版本的 API 接口便于开发使用。
性能评估
将 RKNN 模型在设备上运行,以评估模型在实际设备上运行时的性能,如关注推理速度,CPU占用等。
内存评估
评估模型运行时的内存占用,确保在资源受限的设备上能够正常运行。
量化精度分析
通过 RKNN-Toolkit2 tool 工具我们可以通过ADB工具,远程调试获取 模型量化前后每一层推理结果与浮点模型推理结果的余弦距离,便于分析量化误差是如何出现的,为提高量化模型的精度提供思路。
优化方案
降低模型大小:通过更高压缩率的量化方案或选择速度上更快的模型
| 模型名称 | 输入大小 | 量化方式 | 推理帧数(FPS) | 参数量(m) |
|---|---|---|---|---|
| yolov5n | [1, 3, 640, 640] | INT8 | 39.7 | 1.9 |
| yolov5s_relu | [1, 3, 640, 640] | INT8 | 25.5 | 7.2 |
| yolov5s | [1, 3, 640, 640] | INT8 | 19.3 | 7.2 |
| yolov5m | [1, 3, 640, 640] | INT8 | 8.6 | 21.2 |
以物体检测模型 YOLO 为例,我们可以根据上图观察到不同模型大小的Yolo模型,在准确度相差不大的情况下,选择V5m模型 远不如选择yolov5s模型的推理速度快,直接更换模型版本,降低参数量级,以快速提升推理速度。
分析模型层次性能:通过分析神经网络各层的推理时间,针对性地优化模型结构。
注意到 表格中 出现了yolov5s_relu 模型,在不修改参数量,较小影响识别效果的情况下,通过调整后处理内容,加速模型推理速度。
原因是 观察到在模型推理过程中,部分神经网络层在运行过程中,并没有因量化而获得较大提升,(当然,这也和具体的NPU硬件加速方式密切相关),因此,在这种方案下,我们将部分神经网络层从原先的神经网络中进行修改,将其移动至CPU进行处理,反而能够提升运行速度。
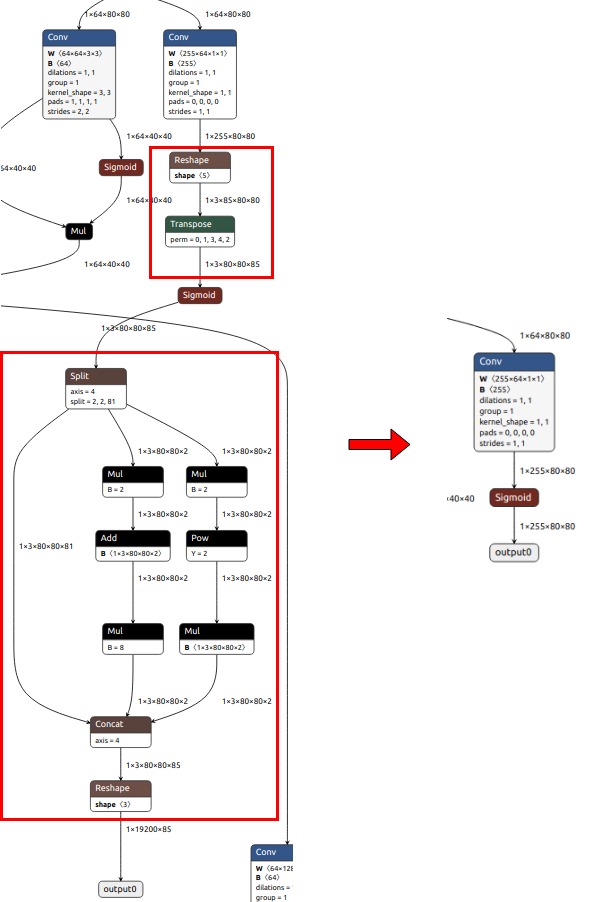
左边是官方原始模型输入输出结构,右边是优化后的模型输入输出结构。
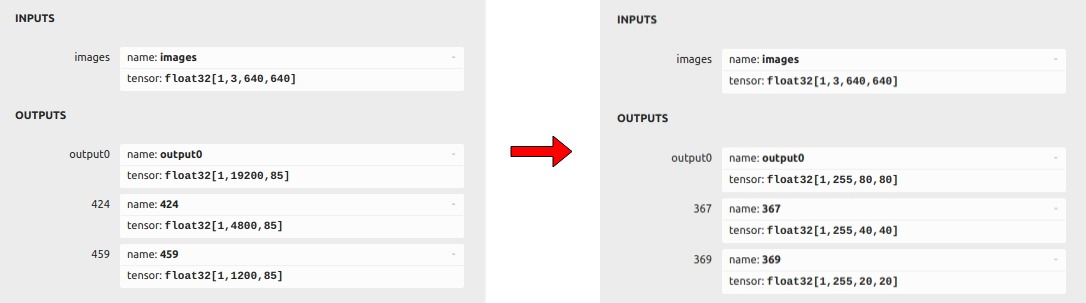
具体而言,我们将红框部分的神经网络处理内容直接删除,作为输出层,最后我们通过在后处理中红框内容执行,已实现速度上的优化。
需要注意,这样调整模型结构后,不可以在使用官方原版本的模型和现有代码运行(显然是因为输入和输出结构已经发生了变化),需要重新简单训练下模型,配合对应的后处理方案,进行模型推理。
多线程优化:在业务中实现多线程并行处理,提升整体推理速度。
如在业务中 需要处理多相机的人员检测,如果按顺序进行单线程检测, 检测周期不能达到1S内,通过分析,排查出问题的主要原因在于所需识别图片的获取时间:约占用500MS,前后处理+推理过程100Ms。
因此通过将 NPU 推理调度流程与图片的获取流程分离,将从多路摄像头中获取识别图片调整为多线程,通过线程安全的队列发送给推理线程进行推理。从而提升程序整体推理速度。
具体部署问题
部署环境与交叉编译环境
支持 NPU 的瑞芯微芯片型号主要有:
RK3562, RK3566, RK3568, RK3588 , RK3576
官方支持在Android 和 Linux 环境下调用其NPU能力,下面以Linux C为例:
开发人员可以通过调用RKNN SDK的API进行编程,并使用交叉编译器编译代码,最终将可执行文件部署到嵌入式设备。
目前瑞芯微官方提供了librknnrt.so 动态库以便我们进行相关推理API调用,值得注意的是 该动态库仅仅提供了 32 位架构下armhf版本和64位架构下 aarch64 版本的动态库,因此需要根据具体环境选择合适的交叉编译工具链。
根据现有交叉编译工具链,推荐使用 arm7.3 或 aarch64-linux 交叉编译器分别在编译32位或64位程序。
NPU运行占用情况查询
cat /sys/kernel/debug/rknpu/load